Big data ваша, сопровождение платформы — наше!
Помогаем снять рутину и обеспечить качество потоков данных с помощью новой услуги DataOps\MLOps-сопровождения
DataOps — относительно новая специализация DevOps для инженеров, работающих с потоками данных. Мы собрали 13 лет опыта в девопсе и экспертизу в работе с данными и упаковали в услугу DataOps-сопровождения.
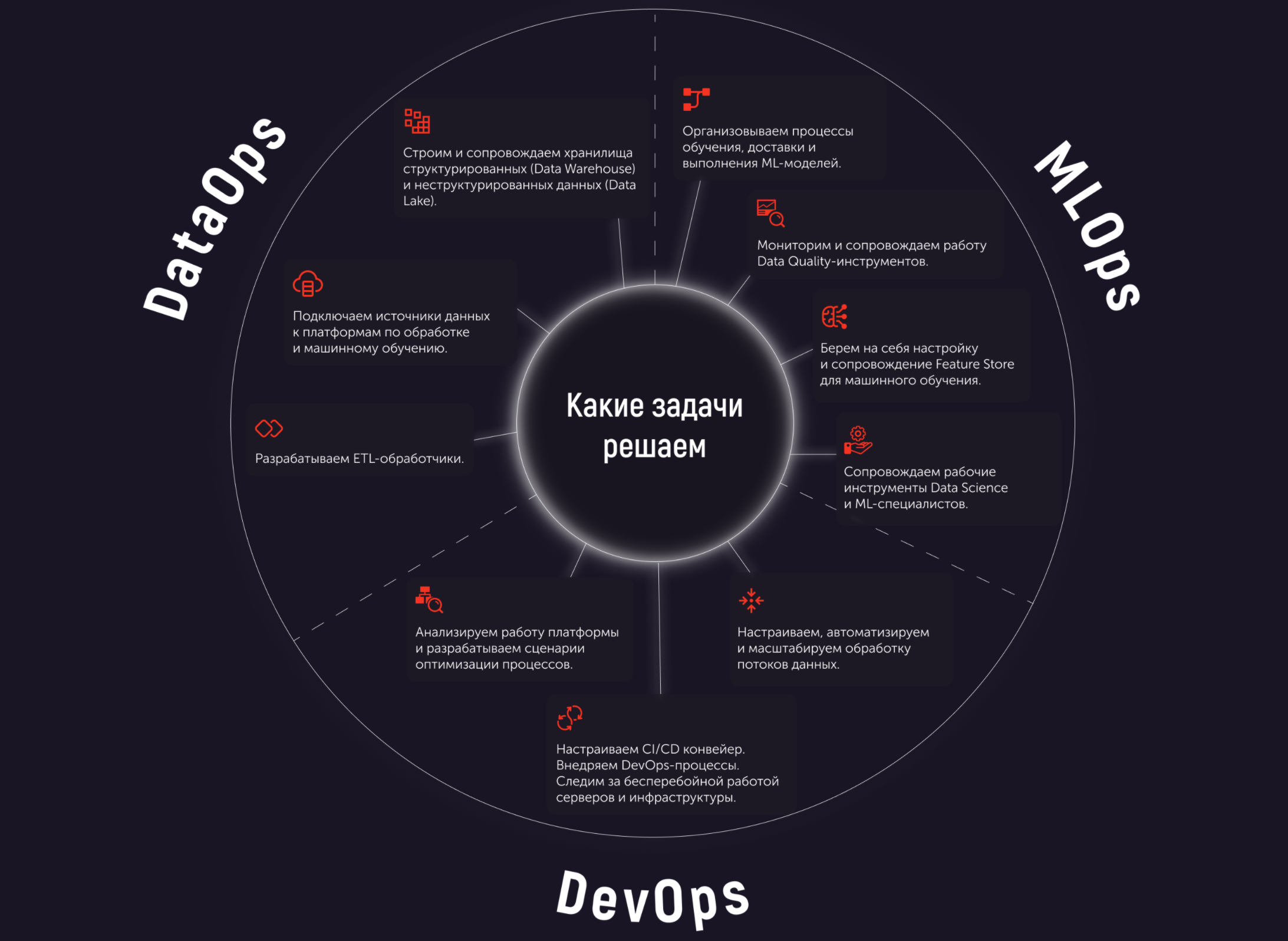
Что предлагаем: полное и круглосуточное сопровождение работы инфраструктур обработки данных. Настроим мониторинг инфраструктуры и потоков данных, при необходимости сделаем витрину для аналитика, напишем ETL-преобразование, подключим источник данных, организуем доставку кода ETL и моделей машинного обучения, настроим деплой “из юпитера куда угодно”. А ещё можем аккуратно перенести всю инфраструктуру из онпрема в облако, если это необходимо.
Зачем это нужно: освободить ваших ценных сотрудников— аналитиков и дата-инженеров — от рутины. Пусть занимаются своими прямыми задачами.
Какая выгода: вы нанимаете целую команду опытных devops-инженеров со специализацией в обработке данных. Они способны решать штатные и внештатные задачи по эксплуатации платформ big data. Владеют акутальным стеком — Apache Kafka, Spak, Airflow, Hadoop, Greenplum, Kubeflow, Redash, Clickhouse. Стоимость их привлечения эквивалентна двум-трём ставкам сисадминов.
Важно в текущей ситуации: мы работаем с опенсорсными системами. Вопрос “что делать, если с поставщиком программного решения что-то случится” для вас потеряет всякую актуальность.
Есть интерес? Тогда вы можете пройти простой опрос про работу с данными в вашем проекте, решаемых задачах и возникающих проблемах. А наши DataOps-инженеры в ответ вышлют вам роадмап по решению указанных в нём проблем.


