
«Инженерия резильентности»: заметки с конференции REDeploy
Пока конференции по всему миру ищут оптимальные форматы в онлайне, самое время вспомнить, как они (да и все мы) жили в довирусную эпоху. В конце прошлого года я посетил конференцию REDeploy 2019, посвященную Resilience Engineering. Очень долго пытался понять, как перевести этот термин на русский, пока не обнаружил, что термин уже давно применяется в неайтишных нишах — как «инженерия резильентности». Дальше следовало бы написать определение резильентности, но одним простым предложением это сделать сложно. А ещё оказалось, что темы, поднятые полгода назад, весьма актуальны и в нашей новой реальности.
Прежде всего, важно понять, что инженерия резильентности — это кросс-дициплинарная область науки, которая целью своей ставит исследование, формализацию и формирование практик, повышающих способность сложных социо-технических систем быть готовыми к нестандартным ситуациям и авариям, адаптироваться к ним и улучшать свои способности к адаптации.
Долгие годы в процессе разработки программного обеспечения превалировала механистическая картина мира — вера в то, что мы способны разработать программное обеспечение, которое будет работать без аварий, а если авария и произойдет, у неё будет некая коренная причина (root cause), исправив которую, можно предотвратить повторение подобных ошибок в будущем — и, таким образом, поскольку число ошибок конечно, в итоге исправить все ошибки, приводящие к авариям (см. отличную статью Dev, Ops и Determinism про это).
Этот же «инженерный» подход применяется и к тому, как взаимодействуют во время аварии люди: достаточно создать некий инструментарий, воспользовавшись которым, люди смогут исправить проблему (при этом не допуская ошибок).
Но загвоздка в том, что программное обеспечение продолжает обновляться, становится сложным, разрозненным и разветвленным, и происходящие аварии не имеют одной единственной причины (более того, могут находится вообще за пределами системы), а люди в процессе коммуникации по исправлению этой аварии могут сами совершать ошибки.
Таким образом, задачей становится не практически невозможное избежание ошибок и аварий в системе, а подготовка людей и системы к тому, чтобы потенциальная авария произвела наименьшее воздействие на систему, её пользователей и создателей.
Разработка программного обеспечения долгое время оставалась в стороне от других «офлайновых» инженерных дисциплин, в то время как практики «снижения вреда» от аварий там применяются уже давно. И эти практики, скорее, относятся к людям, чем утилитам и техническим решениям для предотвращения аварий.
Вопросы, которые задает инженерия резильентности, таким образом, следующие:
- Какие культурные, социальные особенности взаимодействия людей следует учитывать, чтобы лучше понимать, что может, а что не может происходить в коммуникации людей в процессе аварии? Как можно улучшить процесс адаптации и коммуникации? И наоборот, как можно ухудшить ситуацию?
- Какие знания из других дисциплин мы можем применить для того, чтобы сделать систему более гибкой и устойчивой в случае возникновения аварии?
- Каким образом следует организовать подготовку, взаимодействие людей для того, чтобы в случае аварии и ущерб от неё и стресс, для тех, кто будет ее устранять, был наименьшим?
- Какие технические решения, практики можно применить для этого? Каким образом осознанными действиями мы можем повысить устойчивость системы и адаптивность ее к авариям?
Про это и была конференция. А ниже — о чём рассказывали некоторые докладчики.
A Few Observations on the Marvelous Resilience of Bone and Resilience Engineering. Richard Cook
Прежде всего, надо сказать о персоне докладчика. Ричард Кук — врач, ученый и один из главных «популяризаторов» инженерии резильентности в сфере IT. Совместно с Дэвидом Вудсом и Джоном Олспау (человеком, который фактически запустил DevOps как направление) является сооснователем компании Adaptive Capacity Labs, которая занимается внедрением инженерии устойчивости в других организациях.
Надо отметить что REDeploy не совсем IT-конференция, и этот доклад — яркий тому пример.
Большая часть доклада — это подробный анализ того, каким именно образом заживает сломанная кость, заживление которой выступает архетипом резильентности. Сами по себе кости срастаются неправильно. Медицина училась, как лечить переломы, понимая процесс излечения. По сути, медицина даже не занимается лечением самой кости, она занимается созданием процессов, которые способствуют заживлению.
В целом, историю лечения можно разделить на два направления:
- лечение как процесс, создающий максимально благоприятные условия для заживления кости (в процессе лечения мы накладываем гипс, чтобы кость не двигалась).
- лечение как процесс «усовершенствования» процесса заживления (понимая — на биохимическом уровне — как идет процесс заживления, мы применяем такие лекарства, которые его ускоряют).
И здесь главный тезис — по сути, «программного» для всей дисциплины доклада: зачем нам нужно понимать, как протекают социотехнические процессы во время аварии?
Понимая то, как работает механизм «лечения» (например, разрешения аварийной ситуации), мы можем, как минимум, организовать такие благоприятные условия, чтобы авария нанесла минимальный ущерб, а как максимум — ускорить процесс разрешения аварии. Мы не можем предотвратить случаи, когда человек ломает кость, но можем улучшить процесс выздоровления.
The Art of Embracing Failure at Scale. Adrian Hornsby
А теперь уже технический доклад про эволюцию отказоустойчивости в инфраструктуре AWS.
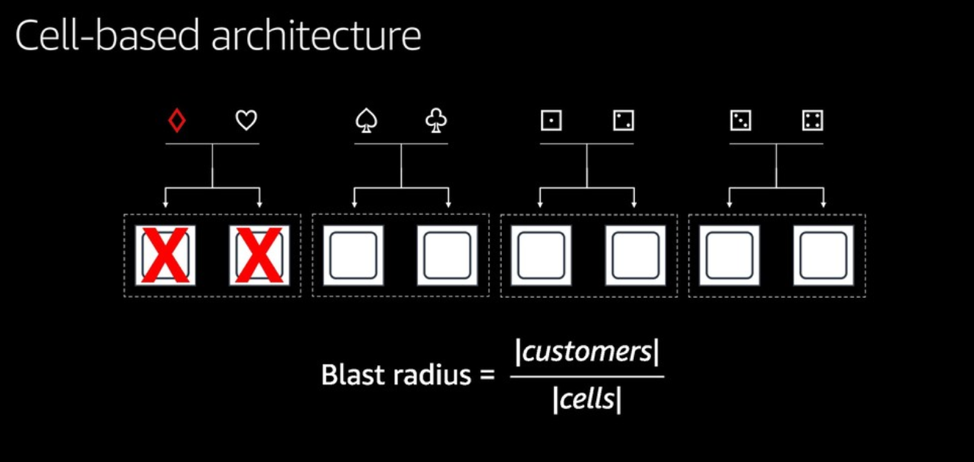
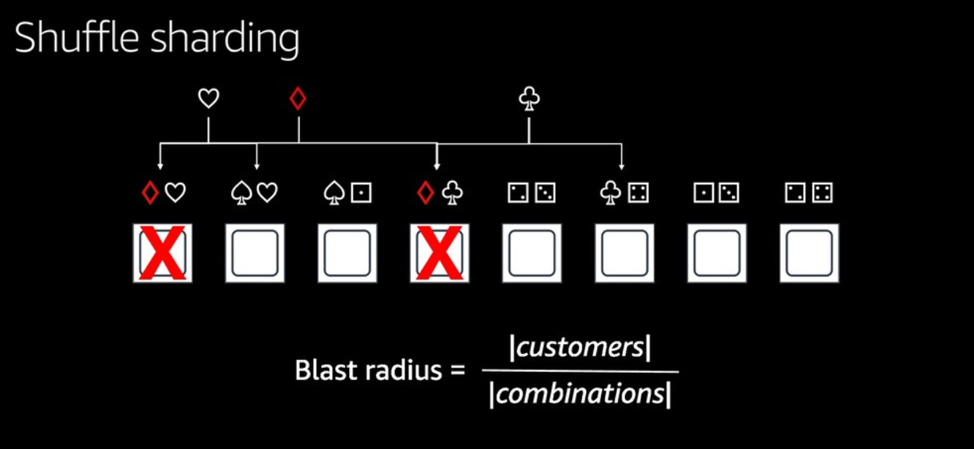
Не вдаваясь в технические особенности (их можно посмотреть в презентации), рассмотрим основной тезис доклада. AWS в процессе построения тех или иных систем разрабатывает архитектуру с учётом того, что авария рано или поздно может произойти, и, соответственно, архитектура системы должна быть разработана таким образом, чтобы максимально ограничить «радиус взрыва» в случае аварии. Например, клиентские базы, хранилища разделены на группы «ячеек», и нагрузка, созданная одним клиентом, влияет только на пользователей этой ячейки. Клиенты в репликах ячеек не дублируют основные ячейки, а перемешаны между собой, таким образом ограничивая радиус удара до минимального.


Getting Comfortable With Being Underwater. Ronnie Chen
Доклад менеджера твиттера с опытом технического глубоководного дайвинга, об особенностях обеспечения безопасности во время погружений.Командные глубоководные погружения — работа, связанная с большим риском. И если в организации таких погружений исходить из возможности погружений только в случае полного нивелирования таких рисков — глубоководных погружений не будет вообще. Так или иначе, проблемы могут произойти, и это нормально — докладчик в целом сравнивает осознанное взятие на себя рисков как метод развития человеческого потенциала. Если мы нивелируем риски, это ограничит наш потенциал. Задача, опять же, состоит в том, чтобы организовать наиболее легкое разрешение ситуаций в случае, если эти риски осуществятся.
Как же можно попытаться жить с тем давлением, которое возлагается на команду в случае осуществления рискованной деятельности?
Пример из правил взаимодействия команды дайверов:
- Надежная и постоянная коммуникация между участниками и максимальное обеспечение психологической безопасности: каждый участник команды должен чувствовать себя в безопасности, любой участник погружения может прекратить погружение в любой момент (и обвинения запрещены).
- Принятие ошибок. Ошибки может допустить любой человек, и ошибки являются неизбежными в процессе работы; обвинения в ошибках также недопустимы.
- Команда может переопределить цели проекта и определение успеха проекта в процессе погружения в зависимости от изменения условий.
- Команда составляется из людей с примерно одинаковой стрессоустойчивостью, действия команды возглавляет наименее опытный участник.
- Формирование опыта каждого участника — одна из важнейших задач. Помимо непосредственно получения опыта, истории об ошибках в погружении рассказываются участниками команды всей команде для того, чтобы на них научиться.
- Постмортемы (те самые истории) существуют не для того, чтобы найти root cause ошибку (которой в большинстве случаев не существует), а для того, чтобы поделиться опытом.
The Practice of Practice: Teamwork in Complexity. Matt Davis
В случае аварии инженеры действуют во многом интуитивно, и интуиция в докладе сравнивается с музыкальной импровизацией. Импровизация — это процесс интуитивного музицирования, но эта интуиция построена на опыте — знании музыкальных гамм, опыте предыдущей импровизации, сыгранности команды. Притом это двунаправленный процесс: интуиция строится на опыте, а на анализе интуитивных действий строятся процессы (в музыке — пишутся ноты сочиненной композиции, в технологиях — описывается процесс исправления аварии).
Два способа обучения/формирования интуиции:
— Постмортемы не как средство обвинения или предотвращения проблемы в дальнейшем, а средство обучения и способ поделиться опытом. Регулярно делитесь опытом решения аварий в виде постмортема/доклада об аварии для того, чтобы передать свой опыт разрешения проблемы другим людям.
— Chaos Engineering как способ формирования опыта в контролируемых условиях. Искусственно создавая аварию в системе, которую надо разрешить, мы формируем опыт интуиции у тех инженеров, которые займутся ее решением. При этом мы можем определить необходимый стек, в котором мы хотим развивать компетенции, ограничивая радиус удара в системе.
Вот самые запомнившиеся мне доклады. Мне кажется, это очень полезные штуки именно сейчас, когда может казаться, что вообще вся реальность поломалась, «несите другую». Возможно, какие-то тезисы помогут вам взглянуть на реальность и на аварии под новым углом.
А ещё я чуть более регулярно, чем блог здесь, веду свой телеграм-канал, подписывайтесь :-)


